确保预测患者疾病风险的算法的公平性
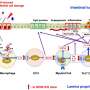
. EO, equalized odds; PCEs, original pooled cohort equations; rPCE, revised PCEs; rUC, recalibrated model; UC, unconstrained model. Credit: <i>BMJ Health & Care Informatics</i> (2022). DOI: 10.1136/bmjhci-2021-100460")
“治疗还是不治疗?”是临床医生不断面临的问题。为了帮助他们做决定,一些人求助于疾病风险预测模型。这些模型基于人口统计因素和医疗数据,预测哪些患者更有可能患病,从而受益于治疗。
随着这些工具的发展医学领域特别是在临床指导这一领域,斯坦福大学和其他地方的研究人员正在努力确保模型底层算法的公平性。当模型没有使用反映不同人群的数据时,偏差就成为一个重大问题。
在一项新的研究中,斯坦福大学的研究人员检查了心血管健康的重要临床指南,这些指南建议使用风险计算器来指导黑人女性、白人女性、黑人男性和白人男性的处方决策。研究人员研究了两种已经提出的提高计算器算法公平性的方法。一种方法,被称为群体再校准,重新调整风险模型对于每个亚组患者,以更好地匹配观察结果的频率。第二种方法被称为均等几率,旨在确保所有组的错误率相似。研究人员发现,重新校准的方法总体上更符合指南的建议。
这些发现强调了构建考虑到与所服务人群相关的完整背景的算法的重要性。
“虽然机器学习在医疗环境和其他社会环境中有很大的前景,但这些技术有可能加剧现有的健康不平等,”斯坦福大学计算机科学博士生、该研究的主要作者阿加塔·福yciarz说英国医学杂志健康与保健信息学.“我们的研究结果表明,评估疾病风险预测模型的公平性可以使它们的使用更负责任。”
除了Foryciarz,研究人员还包括资深作者Nigam Shah,斯坦福医疗保健首席数据科学家和斯坦福HAI教员;谷歌研究科学家Stephen Pfohl和谷歌健康临床专家Birju Patel。
谨慎的预防
本研究评估的临床指南是针对动脉粥样硬化性心血管疾病的一级预防。这种情况是由脂肪、胆固醇和其他物质在动脉壁上形成所谓的斑块引起的。粘稠的斑块会阻碍血液流动,并可能导致中风和肾衰竭等不良后果。
该指南由美国心脏病学会和美国心脏协会发布,为患者何时开始服用他汀类药物提供了建议。他汀类药物可降低导致动脉硬化的某些胆固醇水平。
动脉粥样硬化性心血管疾病指南考虑了包括血压、胆固醇水平、糖尿病诊断、吸烟状况和高血压治疗在内的医疗措施,以及性别、年龄和种族的人口统计数据。根据这些数据,指南建议使用计算器,然后估计患者在10年内患心血管疾病的总体风险。被确定为处于中度或高风险疾病的患者建议开始他汀类药物治疗。对于处于患病边缘或低风险的患者,考虑到潜在的药物副作用,他汀类药物治疗可能是不必要或不需要的。
Foryciarz说:“如果你作为病人被认为比你实际的风险更高,你可以服用你不需要的他汀类药物。”“另一方面,如果你被预测为低风险,但你确实应该服用他汀类药物,医生可能无法采取预防措施,从而预防以后的心脏病。”
临床实践指南越来越多地建议医生对各种疾病和患者群体使用临床风险预测模型。医疗决策支持计算器的普及——例如在手机和其他用于临床的电子设备上——意味着这样的应用程序往往触手可及。
Foryciarz说:“临床医生可能会遇到并使用越来越多的这些基于算法的决策支持工具,所以设计师努力确保这些工具尽可能公平和准确是很重要的。”
细化风险评估
在他们的研究中,Foryciarz和同事们使用了从几个大型数据集中收集的25000多名年龄在40-79岁之间的患者。研究人员将患者动脉粥样硬化的实际发病率与风险模型的预测进行了比较。作为这些实验的一部分,研究人员使用群体重新校准和均衡概率两种方法建立模型,然后将模型计算器生成的估计值与没有公平调整的简单模型计算器生成的估计值进行比较。
分别为四个亚组中的每个亚组重新校准,包括为每个亚组的一个子集运行模型,并获得发生疾病的患者实际百分比的风险评分,然后为更广泛的亚组调整基础模型。对于那些风险水平较低的患者,这种方法确实成功地提高了模型与指南的预期兼容性。另一方面,各子组之间的错误率总体上确实存在差异,尤其是在高风险端。
相比之下,均等几率方法需要建立一个新的预测模型,该模型被限制在整个人群中产生均等的错误率。在实践中,这种方法实现了类似的效果假阳性以及整个人群的假阴性率。假阳性是指被确定为高风险的患者,将开始服用他汀类药物,但没有发生动脉粥样硬化性心血管疾病,而假阴性是指被确定为低风险的患者,但确实发生了动脉粥样硬化性心血管疾病,并可能从服用他汀类药物中受益。
采用这种均等几率方法最终会扭曲各个子组的决策阈值水平。与小组重新校准方法相比,使用考虑到均等几率的计算器将导致更多的他汀类药物处方不足和过度,并不能潜在地防止一些不良结果。
与保持模型原样相比,群体重新校准准确性的提高确实需要额外的时间和精力来调整原始模型,尽管这对于改善临床结果来说是一个很小的代价。另一个警告是,将人口划分为子组确实会增加创建过小的样本量以有效评估子组内风险的可能性,同时也降低了将模型预测扩展到其他子组的能力。
总的来说,算法设计者和临床医生都应该记住哪些公平指标用于评估,如果有的话,哪些用于模型调整。他们也应该明白如何模型或者计算器将在实践中使用以及错误的预测如何导致临床决策,从而产生不良的健康结果。Foryciarz指出,意识到潜在的偏见,并进一步开发公平的算法方法,可以改善所有人的结果。
Foryciarz说:“虽然很难从众多子群体中确定要关注哪一个,但考虑一些子群体总比不考虑要好。”“开发算法来服务于多样化的人群,意味着算法本身必须考虑到这种多样性。”
进一步探索