团队开发工具来更好的个性化的癌症治疗肿瘤细胞进行分类
新的统计模型开发的一个研究小组在伍斯特工学院(WPI)可能使医生能够创建个性化的癌症治疗基于特定的基因突变的患者中发现的肿瘤。
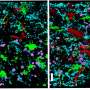
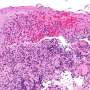
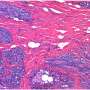
就像癌症不是一个单一的疾病,而是许多疾病的集合,一个单独的肿瘤不可能由一个类型的癌细胞。事实上,导致癌症的基因突变在第一时间也常常导致肿瘤和癌症细胞亚型的混合体。
WPI团队开发了一种新的统计模型使用先进的算法来识别这些多种实体肿瘤的基因亚型分析基因表达数据从一个小活检样本。结果可以帮助塑造更有效的癌症治疗和指导今后的研究。新模型的细节发表在纸”高兴:mixed-membership模型异构肿瘤亚型分类“《华尔街日报》发表的生物信息学。
“今天使用的许多统计模型对肿瘤进行分类的动静极限的方法是有限的,”帕特里克费海提说,博士学位。生物医学工程助理教授在WPI和新文章的资深作者。“换句话说,他们只有一个分类,主要癌症细胞在肿瘤亚型,但这可能会误导人。一种药物,可以针对一个亚型癌症细胞可能不会影响另一个亚型。所以我们着手开发一个模型,可以更准确地预测癌症细胞的多个分数在肿瘤亚型。”
因为癌细胞增殖不受控制基因突变使他们以异常方式成长和逃避身体的自然防御系统。随着肿瘤增长,这些癌细胞繁殖和进化,形成集群不同的亚型。每个子类型可以被产品的独特模式由他们的基因决定的。与DNA测序的成本测试,减少生产这种类型的数据,统计工具需要处理大量数据,并创建相关的信息,医生可以使用实时增加。
“因为临床实验室现在可以病人的癌细胞的基因组序列,预后和治疗正在成为一个大数据的问题,“费海提说。“我们的实验室是侧重于从大数据集提取可操作的信息所以医生和病人可以做出更好的决定。”
报道在他们的论文中,Flaherty的团队开发了一个名为高兴的新模型(高斯拉普拉斯,和狄利克雷的统计分布模型)。他们第一次测试模拟数据集建立像高兴基因表达模式肿瘤的癌细胞的两个亚型。该模型确定正确的分数的两个亚型。接下来,很高兴用基因表达数据准确地确定鼠肺的百分比,大脑和肝脏细胞样本与已知的这些细胞的比例。最后,很高兴被应用于基因表达数据从202年胶质母细胞瘤(人类大脑肿瘤)从癌症基因组图谱项目获得的样本。胶质母细胞瘤的肿瘤被认为有四个亚型的细胞,和高兴准确预测的分数。
展望未来,Flaherty正在探索与临床的合作伙伴是谁治疗乳腺癌癌症病人。希望应用模型基因表达数据随着时间的推移从病人活检,看看结果与病人的结果和所使用的化疗。费海提模型也使完整的高兴可供下载世界各地的同事测试和适用于他们的研究。
“我们期待临床测试,希望在未来几年该模型将有利于医生的治疗组合疗法是有效的对整个肿瘤,“费海提说
进一步探索







用户评论