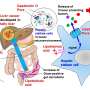
团队开发了绘制基因组功能区域的工具,以更好地了解疾病

如果没有谷歌地图或类似的路线引导技术,我们大多数人都会迷路。当这些地图工具包含额外的交通或天气数据时,我们可以更有效地导航。对于研究哺乳动物基因组以更好地了解疾病遗传原因的科学家来说,结合各种类型的数据集也会让他们更容易找到方法。
索尔克研究所的一个团队开发了一种计算算法,该算法集成了两种不同的数据类型,可以比其他工具更精确地定位基因组中的关键区域。该方法在2017年2月13日的一周内详细描述美国国家科学院院刊,可以帮助研究人员对人类基因组中的致病基因变异进行更有针对性的搜索,比如那些促进癌症或导致代谢紊乱的基因变异。
霍华德休斯医学研究所研究员、索尔克基因组分析实验室主任、资深作者约瑟夫·埃克说:“个体之间的大多数变异都存在于基因组的非编码区域。”“这些区域不编码蛋白质,但它们仍然包含导致疾病的遗传变异。直到现在,我们还没有非常有效的工具来定位各种组织和细胞类型中的这些区域。”
我们的DNA中只有大约2%是由基因组成的,基因编码蛋白质,使我们保持健康和功能。多年来,其他98%被认为是无关紧要的“垃圾”。但是,随着科学开发出更复杂的工具来探测基因组,很明显,许多所谓的垃圾都起着至关重要的调节作用。例如,DNA中被称为“增强子”的部分决定了基因信息何时何地被读出。

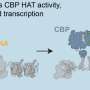
增强子的突变或破坏越来越多地与人类疾病的主要原因联系在一起,但增强子很难在基因组中定位。关于它们的线索可以在某些类型的实验数据中找到,比如调节基因活性的蛋白质的结合,DNA包裹的蛋白质的化学修饰(称为组蛋白),或者DNA中存在的称为甲基的化合物,它们打开或关闭基因(一种称为DNA甲基化的表观遗传因素)。通常,寻找增强子的计算方法依赖于组蛋白修饰数据。但是Ecker的新系统,称为REPTILE(“基于组织特异性局部表观基因组特征的调控元件预测”),结合组蛋白修饰和甲基化数据来预测基因组的哪些区域包含增强子。在该团队的实验中,REPTILE在发现增强子方面比仅依赖组蛋白修饰的算法更准确。
“这种方法的新奇之处在于,它使用DNA甲基化来真正缩小组蛋白修饰数据所建议的候选调控序列,”索尔克研究生、该论文的第一作者何宇鹏(Yupeng He)说。“然后,我们能够在实验室中测试REPTILE的预测,并用实验数据验证它们,这让我们对算法找到增强子的能力有了高度的信心。”
REPTILE算法一般分为两个步骤:训练和预测。在训练中,索尔克团队通过向算法中输入已知增强子的位置以及DNA中增强子以外的基因组区域,教REPTILE识别哺乳动物增强子。在预测步骤中,该算法在9个增强子区域未知的小鼠和5个人类细胞系和组织上运行,并精确定位潜在增强子的位置。最后,该团队利用实验室实验的数据来测试REPTILE在预测步骤中所做的预测是否与真实的调控区域相对应。由于增强子增加了目标基因的活性,研究人员可以通过将DNA序列连接到报告基因并观察假设的目标基因是否增加来测试DNA序列的活性。利用分子工具,该团队改造了小鼠胚胎,使增强子激活可以触发相关报告子的表达,这可以通过染色来监测。因此,如果REPTILE预测到一种特定的增强子与小鼠前脑发育有关,研究小组就能够在胚胎的前脑区域寻找染色模式。如果他们看到了,REPTILE的预测就被认为是有效的。Salk团队还将REPTILE的预测与其他四种常用的增强子寻找算法进行了测试。总的来说,REPTILE的表现优于每一个,发现增强子区域的准确性更高(沿着DNA链靠近它们),错误(错误识别)更少。 In particular, REPTILE was more successful than the other systems at the invaluable task of finding enhancers in different tissue types than those it was trained on.
“基因组中遗传变异的数量是巨大的,”埃克说。“所以在寻找导致疾病的基因方面,你真的想把聚光灯放在你认为最重要和最具识别性的区域上增强剂是这个过程中的关键一步。”