卫生保健研究人员必须警惕滥用人工智能
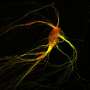
 and a true effect (black line), a statistical model aims to estimate the true effect. The red line exemplifies a close estimation, whereas the blue line exemplifies an overfit ML model with over-reliance on outliers. Such a model might seem to provide excellent results for this particular dataset, but fails to perform well in a different (external) dataset. Credit: <i>Nature Medicine</i> (2022). DOI: 10.1038/s41591-022-01961-6")
一个国际研究团队在该杂志上写道自然医学他建议,在医疗保健研究中,需要特别注意不要滥用或过度使用机器学习(ML)。
“我绝对相信ML的力量,但它必须是一个相关的补充,”这篇评论的第一作者、来自荷兰伊拉斯谟MC大学医学中心的神经外科医生和统计编辑维克多·沃洛维奇博士说。“有时ML算法的表现并不比传统的统计方法更好,导致论文发表缺乏临床或科学价值。”
现实世界的例子表明,在医疗保健领域滥用算法可能会使人类的偏见永久化,或者在机器接受有偏见的数据集训练时无意中造成伤害。
许多人认为,机器学习将彻底改变医疗保健,因为机器做出的选择比人类更客观。但如果没有适当的监督,ML模型可能弊大于利,”该评论的高级作者、来自新加坡杜克-新加坡国立大学医学院定量医学和卫生服务与系统研究项目中心的副教授Nan Liu说。
“如果通过ML,我们发现了我们在放射学和病理学图像中看不到的模式,我们应该能够解释算法是如何做到这一点的,以实现制衡。”
与来自英国和新加坡的一组科学家一起,研究人员强调,尽管已经制定了指导方针来规范ML在中国的使用临床研究这些指南只在决定使用ML时适用,而不是首先询问是否或何时使用ML是合适的。
例如,一些公司已经成功地训练ML算法使用数十亿张图像和视频识别人脸和道路物体。但当涉及到它们在医疗保健环境中的使用时,它们通常会接受数十、数百或数千个数据的培训。研究人员写道:“这凸显了医疗保健大数据的相对贫困,以及努力实现其他行业已达到的样本量的重要性,以及协调一致的国际大数据共享健康数据的重要性。”
另一个问题是,大多数ML和深度学习算法(没有收到关于结果的明确指令)通常仍然被视为“黑箱”。例如,在COVID-19大流行开始时,科学家发表了一篇文章算法这可以通过肺部照片预测冠状病毒感染。后来发现,算法是根据照片中字母“R”(代表“右肺”)的印记得出结论的,这些字母总是在扫描图像上的一个略微不同的位置被发现。
“我们必须摆脱ML可以发现我们无法理解的数据模式的想法,”沃罗维奇博士谈到这一事件时说。“ML可以很好地发现我们不能直接看到的模式,但你必须能够解释你是如何得出这个结论的。为了做到这一点,算法必须能够显示它采取了哪些步骤,这就需要创新。”
研究人员建议,ML算法在用于临床研究之前,应该与传统的统计方法(如果适用)进行评估。在适当的时候,他们应该补充临床医生的决策,而不是取代它。研究人员写道:“ML研究人员应该认识到他们的算法和模型的局限性,以防止它们的过度使用和滥用,否则可能会播下不信任的种子,并造成患者伤害。”
这个团队正在组织一个国际努力为ML和传统统计学的使用提供指导,并建立一个可以利用ML算法的强大功能的大型匿名临床数据数据库。
进一步探索