学习用机器学习方法与感染作斗争

科学的进步通常因需要大量数据的需求而阻碍,这可能是昂贵的,耗时的,有时甚至难以收集的。但是,在研究我们的身体如何与疾病作斗争时,可能有一个解决方案:一种称为Motifboost的新机器学习方法。这种方法可以帮助解释T细胞受体(TCR)的数据,以识别过去的特定病原体感染。通过专注于TCR中的简短氨基酸序列的集合,研究团队通过较小的数据集获得了更准确的结果。这项工作可能会阐明人类免疫系统识别细菌的方式,这可能会改善健康结果。
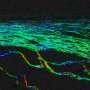
最近的大流行强调了人体反击新威胁的能力的重要性。自适应免疫系统使用专门的细胞,包括T细胞,这些细胞制备了一系列不同的受体,这些受体即使在第一次到达之前就可以识别特定于入侵细菌的抗原。因此,受体的多样性是一个重要的调查主题。但是,他们识别的受体和抗原之间的对应关系通常很难通过实验确定,并且如果未提供足够的数据,当前的计算方法通常会失败。
现在,东京大学工业科学研究所的科学家开发了一种新的机器学习方法,可以预测一种感染捐赠者基于TCR的有限数据。小主题集中在每个受体中的非常短的片段,称为K-mers。尽管科学家考虑的蛋白质基序通常更长,但小组发现,提取三个连续氨基酸的每种组合的频率非常有效。第一作者Yotaro Katayama说:“我们在小规模数据集接受培训的机器学习方法可以补充只能在非常大的数据集上起作用的常规分类方法。”主题启发的灵感来自以下事实:不同的人通常在暴露于同一病原体时产生相似的TCR。
首先,研究人员采用了一种无监督的学习方法,在该方法中,根据数据中发现的模式自动对捐助者进行分类,并表明捐赠者使用K-MER分布形成了不同的群集,基于巨细胞病毒(CMV)先前感染的K-MER分布。由于无监督的学习算法没有有关哪些捐赠者感染CMV的信息,因此该结果表明K-MER信息有效地捕获患者免疫状态的特征。然后,科学家使用K-MER分布数据进行监督的学习任务,其中算法获得了每个捐赠者的TCR数据,以及捐赠者感染了特定疾病的标签。然后对该算法进行训练以预测看不见的样品标签,并测试了CMV和HIV的预测性能。
“我们发现现有的机器学习方法可能会因学习不稳定性而遭受降低的准确性,而当样本数量降至一定临界大小以下时。相反,主题启动在大数据集中同样同样执行,并且仍然在小型小型数据集中提供了很好的结果数据集,”高级作家Tetsuya J. Kobayashi说。这项研究可能导致基于T细胞组成的病毒暴露和免疫状态的新测试。
这项研究发表在免疫学领域作为“曲目分类方法的比较研究揭示了K-MER特征提取的数据效率”。