2021年4月2日特征
研究人员发现,罕见的奖励会放大学习过程中的多巴胺反应
 Schematic drawings of the uniform (left) and normal (right) reward probability distributions. The expected values (EV) and positive and negative prediction errors (+PE and -PE, respectively) are all identical in both distributions. The only difference between the reward distributions is how frequently +PE and -PE occur. B) The responses from one dopamine neuron to identical rewards drawn from uniform (green) and normal (magenta) reward distributions. The top section shows Peri-Stimulus Time Histograms (PSTHs) aligned onto reward delivery (vertical dashed lines). The bottom section shows raster plots where every tick mark represents the timing of an action potential. The raster plots and PSTHs show that the larger rewards evoke positive prediction error response – the activations above zero – whereas smaller rewards evoke negative prediction error responses – the responses that dip below zero. Note that, despite + and – PE being identical in uniform and normal distributions, the responses to rewards drawn from the normal distribution are amplified, relative to the responses to rewards drawn from the uniform distribution. Thus, rare rewards amplify dopamine responses. Credit: Rothenhoefer et al.")
过去的研究一直突出了多巴胺神经元在奖励学习中的关键作用。奖励学习是一种过程,人类和其他动物通过在执行特定行动后接收奖励或向一个问题提供“正确”/期望的响应后,人类和其他动物通过接收奖励来获取不同的信息,技能或行为。
当个人接受比他们期望接收的更好的奖励时,多巴胺神经元被激活。相反,当他们收到的奖励比他们预测的奖励时,多巴胺神经元被抑制。这种特定的活动模式类似于所谓的“报酬预测误差,“所接收的奖励与预测的基本上存在差异。
匹兹堡大学的研究人员最近进行了一项研究调查奖励和奖励预测误差的频率可能会影响多巴胺信号。他们的论文,发表在自然神经科学,为奖励学习的多巴胺相关的神经内衬提供新的和有价值的洞察力。
“奖励预测错误对动物和动物至关重要机器学习,“William R. Stauffer,Ph.D.是一项研究的研究人员,告诉Medical Xpress。然而,在古典动物和机器学习理论中,”预测奖励“部分的等式简单地欧宝娱乐地址是平均值过去结果的价值。虽然这些预测是有用的,但预测平均值是更有用的,以及反映不确定性的更复杂的统计数据。
研究人员通过Wolfram Schultz,Wellcome Principal研究员(剑桥大学)和Stauffer的后医生导师的神经科学教授Wellcome Chinalipal研究员Welfram Schultz,从2005年发表的一项研究中吸引了灵感。今年2005年的研究表明,多巴胺奖励预测误差响应根据标准偏差,舒尔茨及其同事作为最大和最小的结果之间的范围。
“这项研究是突破性的,因为它表明神经元预测实际上反映了不确定性,”Stauffer说“然而,有几种不同的方式调节不确定性,我怀疑他们不是心理上等价物。”
舒尔茨和他的同事在他们的研究中使用的范围调制(改变标准差)使每个潜在的奖励都具有相同的预测概率。
“如果范围是恒定的,我们很想知道多巴胺神经元会如何应对多巴胺神经元,但在该范围内的奖励的相对概率发生变化,”Stauffer说。“因此,我们研究的主要目的是了解多巴胺神经元是否对概率分布的形状敏感。”
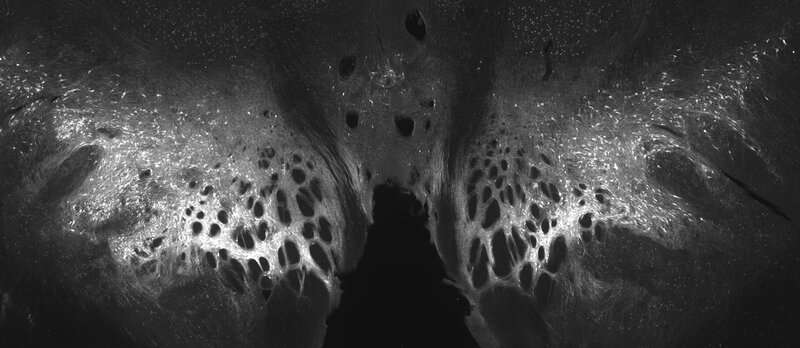
在他们的实验中,Stauffer和他的同事使用两种不同的视觉线索来预测从两种不同的“奖励概率分布”中获得的奖励。这两种虚拟分配都包含三种类型的奖励,即小型、中型和大型果汁掉落。
然而,其中一个奖励概率分布类似于正常分布,其中中心值(即中等汁液滴)在大多数试验中递送,而小型和大的果汁液滴则很少递送。另一方面,第二奖励概率分布随之称为“均匀分布”,其中小,培养基和大奖励以相同的概率(即,相同的次数)。
使用电极,Stauffer和他的同事记录了多巴胺响应,而猴子正在观看与两种不同奖励概率分布的奖励相关的视觉提示。当猴子接收来自虚拟奖励概率分布的奖励“绘制”时,它们还记录了多巴胺响应。
值得注意的是,研究人员观察到,用较低的频率(即罕见奖励)施用的奖励扩增了猴子的大脑中的多巴胺反应。相比之下,完全相同的卷曲,但随着更大的频率诱发多巴胺反应。
“我们的观察意味着预测神经元信号反映了周围预测的不确定性水平,而不仅仅是预测值,”Stauffer表示。“这也意味着大脑中的主要奖励学习系统中的一个可以估计不确定性,并且可能教导关于这种不确定性的下游脑结构。我们有很少的其他神经系统,我们具有神经元反应的算法性质的这种直接证据。这些迷人的结果表示神经算法的一个新方面。“
该研究人员执行的研究突出了奖励频率的影响多巴胺奖励学习过程中产生的反应。这些发现将为进一步的研究提供参考,这将显著增强目前对奖赏学习神经机制的认识。
最终,研究人员希望探讨如何应用于在歧义下的选择(即,当成果概率未知时的选择)。在这些具体的决策方案中,人类通常被迫根据他们对奖励概率分布的信念来做出决策。
“这项研究是了解主观奖励概率分布如何在大脑中编码的第一步,以及这些信仰可以采取的形式,”Stauffer说。“通过这些结果,我们现在将回到学习选择。尽管如此,我怀疑这些结果将具有更广泛的影响,对生物和人工智能的学习系统也很重要。”
进一步探索
©2021科学欧宝app网彩X网络











用户评论