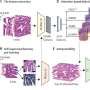
“自学成才”的深度学习提高疾病诊断

新工作由计算机科学家在劳伦斯利弗莫尔国家实验室(LLNL)和IBM研究深度学习模型来准确地诊断疾病与不带安全标签的数据时赢得了x射线图像的计算机辅助诊断最佳论文奖学报医学影像会议2月19日。
技术,包括新的正则化和“自我训练”策略,解决一些著名的挑战,采用人工智能(AI)疾病诊断,即难以获得丰富的带安全标签的数据时由于成本、工作或隐私问题和内在抽样偏差在收集到的数据,研究人员说。目前人工智能算法也不是能够有效地诊断中不能充分代表的条件训练数据。
LLNL计算机科学家Jay Thiagarajan说团队的方法表明,精确模型可以创建标签有限的数据和执行或甚至比神经网络更大的标签数据集训练。学报出版的论文,包括合作者在IBM阿尔马登在圣何塞的研究。
“建设预测模型在卫生保健迅速变得越来越重要,”Thiagarajan解释道。“我们试图解决一个基本问题。数据来自不同的医院和很难label-experts没有时间收集和注释。通常是构成多标记分类问题,我们正在考虑多种疾病的存在在一个镜头。我们等不及要有足够的数据,每一个疾病的组合条件,所以我们建立了一个新的技术,试图弥补缺乏数据使用正则化策略可以使深度学习模型更有效,即使在有限的数据。”
在论文中,研究小组描述了一个框架,利用策略包括数据增加、信心回火和自我训练,最初的“老师”模型专门学习用标记成像数据,然后火车第二代“学生”模式同时使用标记数据和额外的无标号数据,根据指导老师。这第二代模型执行比教师模型、Thiagarajan解释说,因为它看到更多的数据,和老师能够提供pseudo-supervision。然而,这种方法可以容易确认偏误(即不正确的指导老师),由信心回火处理和数据增强策略。
研究小组将他们的学习方法基准数据集包含标记数据和未标记数据的胸部x光诊断五个不同的心脏病:心脏肥大、水肿、整合、肺不张及胸腔积液。研究人员看到减少85%所需的标签数据达到相同的性能的现有最先进的神经网络训练对整个数据集的标签。这很重要,在收集的临床应用人工智能标记数据可以极具挑战性,Thiagarajan说。
“当你有有限的数据,提高模型处理数据的能力还没有见过的是我们不得不考虑的关键方面解决有限的数据问题,”他解释道。“这不是关于模型X和Y,它是关于从根本上改变我们这些模型训练的方式,还有更多的工作需要做在这个空间对我们实际用例实现有意义的诊断模型在卫生保健。”
Thiagarajan警告称,尽管技术是广泛适用,研究结果不一定适用于每一个医学分类或分割问题。然而,他补充说,这是一个“有前途的第一步”民主化AI models-creating模型能够应用广泛的疾病情况,常见和罕见的类型。最终,一个有效的模型需要训练有限带安全标签的数据时,推广范围广泛的条件和支持多种疾病的同时预测,Thiagarajan补充道。
Thiagarajan说,团队的下一个步骤是使用领域知识来提高拟议的框架和address类失衡通过进一步勘探的数据扩充和暴露模型更多的变化,从而使他们适用于更广的范围。