基准测试AI回答医学问题的能力
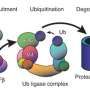
 on MedQA (four options), MedMCQA and PubMedQA datasets. The previous state-of-the-art results are from Galactica20 (MedMCQA), PubMedGPT19 (MedQA) and BioGPT21 (PubMedQA). The percentage accuracy is shown above each column. Credit: Nature (2023). DOI: 10.1038/s41586-023-06291-2")
基准评估如何大型语言模型(llm)可以回答医疗问题发表的论文中提出自然。从谷歌的研究,这项研究还介绍Med-PaLM, LLM专门用于医学领域。然而,作者指出,许多限制之前必须克服llm可以成为临床应用的可行性。
人工智能(AI)模型在医学上有潜在用途,包括知识检索和临床决策支持。例如,然而,现有的模型可能产生幻觉令人信服的医疗错误或偏见,可能会加剧健康差异。因此,评估他们的临床知识是非常必要的。不过,这些评估通常依靠自动化评估基准有限,个人医疗测试得分等可能不会转化为现实的可靠性或价值。
llm编码表现进行评估的临床知识,卡兰辛格尔Shekoofeh阿齐兹,道你,艾伦•Karthikesalingam Vivek Natarajan和他的同事们认为这些模型回答医学问题的能力。
称为MultiMedQA作者提供一个基准,结合现有六个问答数据集生成专业的医学研究和消费者查询,和HealthSearchQA, 3173年一个新的数据集医疗问题通常在线搜索。
作者然后评估棕榈(5400亿参数LLM)的性能及其变种,Flan-PaLM。他们发现Flan-PaLM实现先进的性能的几个数据集。MedQA数据集包括美国医疗许可试题风格问题,FLAN-PaLM超过之前的最先进的llm 17%以上。然而,尽管FLAN-PaLM表现良好在多项选择题,人类评估显示空白的长篇消费者医疗问题的答案。
来解决这个问题,作者使用了一种叫做指令及时调整进一步Flan-PaLM适应医疗领域。指令提示优化介绍作为一个有效的方法调整多面手llm新的专业领域。
他们产生的模型、Med-PaLM表现令人鼓舞的是飞行员的评价。例如,一组临床医生判断只有61.9%的Flan-PaLM长篇的答案是一致的科学共识,相比之下,92.6% Med-PaLM答案,与clinician-generated答案(92.9%)。同样,29.7%的Flan-PaLM答案被认为可能导致有害的结果,为Med-PaLM 5.8%相比,比得上clinician-generated答案(6.5%)。
作者指出,虽然他们的研究结果是有前途的,进一步的评估是必要的。
更多信息:卡兰Singhal et al,大型语言模型编码的临床知识,自然(2023)。DOI: 10.1038 / s41586 - 023 - 06291 - 2