研究人员开发了一种新的方法来识别复杂的医学关系

一组来自退伍军人事务部、橡树岭国家实验室、哈佛大学陈氏公共卫生学院、哈佛医学院和布里格姆妇女医院的研究人员开发了一种新颖的、基于机器学习的技术,利用多个医疗保健提供者的电子健康记录数据来探索和识别医疗概念之间的关系。
该方法被称为通过稀疏嵌入回归的知识提取,或KESER,最近发表在npj数字医学.该流程集成了来自两大机构——VA和波士顿Partners医疗保健——的电子健康记录数据,并提供自动特征选择,从而导致表型识别算法和知识发现。
“KESER为临床知识之间的关系提供了一个高水平的视角,这是我们在个人或群体层面护理患者时无法总是看到的,”Katherine Liao博士说,她是波士顿VA KESER的首席研究员,也是哈佛医学院的医学副教授。“我们期待将这项研究的方法和结果从临床研究的应用转化为临床护理的进步。”
该项目是表型学核心工作的一部分。Kelly Cho和Mike Gaziano来自波士顿和哈佛的退伍军人协会,他们参加了退伍军人协会百万老兵项目,简称MVP,这是一个“研究基因、生活方式和军事暴露如何影响健康和疾病的国家研究项目”,根据退伍军人协会MVP研发办公室的网站。
2016年,ORNL开始与退伍军人管理局在MVP项目下的大数据项目MVP- champion上合作,创建一个大型的精准医疗平台,以托管退伍军人管理局的大量医疗记录数据集其中包括约2,400万退伍军人的记录。为了加强跨领域创新,支持该VA- doe联合项目下的众多研究项目,ORNL与来自VA Boston和Harvard的MVP Data Core密切合作,确定具体的研究领域。其中一项努力是回答以下问题:我们需要在电子健康记录中找到哪些元素才能正确识别给定的表型?
研究团队利用他们认为是美国用于这类研究的最大的医疗保健数据队列,着手自动识别表型关系,同时提供潜在的机器学习假设和决策过程的可见性。
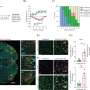
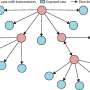
为此,他们设计并构建了四步KESER方法:将数据转换为结构化格式,构建每种格式的低维向量表示医学的代码,选择特征来属性重要性,并将属性关系映射为网络.
数据处理与表示学习
ORNL在处理和构建各种医疗数据(病人程序、诊断和测量、医生记录、处方信息等)方面发挥了关键作用,这些数据来自退伍军人管理局和合作伙伴医疗保健部门的数百万患者。
ORNL人工智能系统部门主管、MVP-CHAMPION项目首席研究员Edmon Begoli表示:“在得到结构化信息之前,需要进行大量的非结构化数据处理,这些信息可以被放入统计方法中。”“该团队花了多年时间研究这些数据,使其达到可以开始用于研究的状态。”
使用处理过的数据,该团队构建了一个共发生矩阵,由超过100,000种事件类型或医疗保健代码组成——本质上是一个庞大但稀疏的数据表,其中包含每个可能的医疗保健代码的行和列。两个事件之间的每一次同时发生都有助于创建一个给定表型的更清晰、更详细的图像。
利用ORNL的大数据基础设施和科学计算方面的专业知识(在处理如此大规模的数据时必不可少),该团队努力实现数据预处理的自动化,并将该过程公之于众。
“研究人员或机构可以下载代码,以正确的格式存储他们的数据,我们的流程将完成所有必要的步骤,将他们的数据与其他所有人的数据集成,”ORNL研究科学家和该项目的首席数据工程师埃弗雷特·拉什(Everett Rush)说。
研究团队在整个项目中都非常注意保护患者的隐私。该团队在ORNL的安全保护健康数据基础设施中处理了所有VA的数据。在把它分解成一个匿名的总结级别后,他们与哈佛大学和其他合作者分享了它。得到的KESER矩阵与个别患者没有联系。
ORNL高级解决方案工程师达拉斯·萨卡说:“我们无法从最终结果追踪到单个患者,因为这些都是集合。”Sacca在ORNL管理受保护的健康数据飞地,并审查每条数据,确保在允许其离开飞地之前符合HIPAA去识别指南。
知识提取
矩阵中充满了关于这一庞大患者队列的匿名信息,可以用不同的方法(如KESER)进行研究,以获得对人类健康的新见解。利用一系列现代统计方法,研究小组将汇总数据转换为向量,调整模型,编码每个向量的相关性,提取每种表型的最重要特征和特征权重。
ORNL高级研究科学家和MVP-CHAMPION项目的首席统计学家George Ostrouchov说:“这些统计方法,包括用于协方差结构稀疏建模的高斯图形模型,在揭示潜在因果关系的重要性归因方面特别有能力,这是深度学习等经典人工智能技术往往难以应对的概念。”
在运行KESER方法后,该团队选择了8个表型包括抑郁症、类风湿性关节炎和溃疡性结肠炎。利用KESER选择的特征,他们训练模型来识别感兴趣的表型。
未来的研究
KESER能够匿名化、整合和分析来自多个卫生保健机构的数据,这种新颖的能力带来的可能性似乎是无限的。
哈佛医学院生物医学信息学教授、KESER的首席研究员蔡天喜(音)说:“我们很高兴有一种高度可扩展的方法,可以处理比我们现在工作的矩阵大一个数量级的矩阵。”
该团队已经将更多的临床描述符纳入到知识图谱中。此外,该团队已经开始探索知识图表,以更好地理解新出现的疾病。
杜克大学(Duke University)助理教授洪川(Chuan Hong)说:“在像COVID这样的情况下,每个人都需要共享数据,我们需要开始调查与这种特定疾病相关的所有不同的事情,你可能可以用这个系统做到这一点。”洪川去年在哈佛担任讲师,领导了KESER项目的研究。“这基本上是即插即用;你进入数据仓库,遵循四步流程,直接集成你的结果。”
未来合作和发现的潜力可能是该项目最大的成功。“这项创新将促进多中心合作,”该团队在报告中写道自然,“并使该领域更接近于创建分布式网络,以便在保持患者隐私的情况下跨机构学习。”