与其他声音相比,人类的大脑更能及时地追踪语言

人类可以毫不费力地识别并对自然声音做出反应,特别是对语音。有几项研究旨在本地化和理解speech-specific部分的大脑,但相同的大脑区域大多是活跃的所有声音,目前仍不清楚是否大脑有独特的语音处理的过程,以及它如何执行这些过程。其中一个主要的挑战是,当两者之间没有一对一的对应关系时,大脑是如何将高度可变的声音信号与语言表征相匹配的——如何将由非常不同的讲话者和方言说出的相同单词识别为相同的。
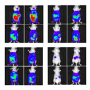
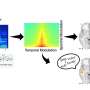
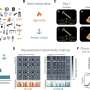
在这项最新的研究中,由Riitta Salmelin教授领导的研究人员以毫秒为单位解码和重建了口语词汇大脑16名健康芬兰志愿者的录音他们采用了一种新颖的方法,利用各种声音的自然声学变异性(由不同的说话者说出的词语,来自不同类别的环境声音),并利用生理启发将它们映射到脑磁图(MEG)数据机器学习模型。这些类型的模型,具有时间分辨和时间平均的声音表征,以前被用于大脑研究。该研究的主要作者之一Ali Faisal提出了一种新颖的、可扩展的构想,允许将这种模型应用到全脑录音中,而这项研究是第一次将同样的模型用于语音和其他声音的比较。
阿尔托研究人员、第一作者安妮·诺拉说:“我们发现,大脑皮层激活对展开语音输入的时间锁定对语音编码至关重要。”当我们听到一个单词时。“猫”,我们的大脑必须及时非常准确地跟踪它才能理解它的意思。
与之形成对比的是,时间锁定在大脑皮层对非言语环境声音的加工中并不突出口语词汇,比如音乐或笑声。相反,时间平均分析足以达到它们的意义。”这意味着相同的表示(一只猫的样子,它如何感觉等)访问的大脑也当你听到一只猫喵声,但是声音本身是作为一个整体进行分析,不需要类似time-locking大脑激活的,诺拉解释道。
对无意义的新单词也进行了时间锁定编码。然而,即使是对人类发出的非语言声音(如大笑)的反应,动态锁定机制也没有显示出解码的改进,而使用平均时间机制可以更好地重构模型,这表明锁定时间编码是专门用于识别为语音的声音。
结果表明,大脑反应跟随语言以特别高的时间保真度
目前的结果表明,在人类中,一种特殊的锁定时间的编码机制可能已经进化为语言。根据其他研究,这种处理机制似乎与在早期发育期间广泛接触语言环境的母语相适应。
目前发现的时间锁定编码,特别是语音编码,加深了对声学和语言表征(从声音到单词)之间映射所需计算的理解。目前的研究结果提出了这样一个问题:声音中哪些特定的方面对提示大脑使用这种特殊的编码模式至关重要。为了进一步研究这一点,研究人员下一步的目标是使用现实生活中的听觉环境,比如重叠的环境声音和语音。诺拉说:“未来的研究还应该确定,是否可以通过经验观察到类似的时间锁定在处理其他声音方面的特殊性,比如音乐家对器乐声音的处理。
未来的工作可以研究语音声学中不同性质的贡献,以及在声音处理中使用时间锁定或时间平均模式的实验任务可能产生的影响。这些机器学习模型在应用于临床群体时也可能非常有用,比如调查受损个体演讲处理。
进一步探索














用户评论