大脑使用内部“平均语音”原型来识别谁在说话
(欧宝娱乐地址医学Xpress) - 根据神经科学家的说法,人脑能够通过将个人的声音与内部“平均语音”原型进行比较来识别个人的声音。
格拉斯哥大学研究人员进行的一项研究,并在《杂志》中报道当前的生物学证明语音身份是通过参考两个内部语音原型来编码在大脑中的 - 一名男性,一名女性。
声音与原型具有最大差异的差异更为独特,并产生更大的神经活动比声音被认为非常相似。
神经科学与心理学研究所的研究人员通过将32个同性的声音共同产生语音原型来进行研究,从而产生了平稳,理想化的声音,几乎没有违规。
然后,他们通过更改原型语音的“距离均值”来产生不同的声音 - 例如,将音调和音调或变形两个或多个声音一起变形。
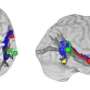
使用功能性磁共振成像(fMRI),研究人员能够看到神经活动的增加,声音的原型越远。
帕斯卡尔·贝林教授说:“像面孔一样,可以使用声音来识别一个人,但是这种能力的神经基础仍然很少理解。在这里,我们提供了大脑用来识别说话者的基于规范的编码机制的第一个证据。
“研究表明,这是识别面部的类似过程,在该过程中,大脑还使用平均面部与它遇到的其他面孔进行比较以建立身份。
“因此,不必记住每天听到的每一个声音,而是脑通过仅记住与其存储的原型的差异来促进识别任务。
“这导致了一系列有趣且重要的问题,例如原型是否是先天的,存储的模板,或者它们是否受到环境和文化影响。原型可以包含一个人生中所有声音经历的平均水平?”
这项研究“基于规范的人类听觉皮层的语音身份编码”得到了生物技术和生物科学研究委员会(BBSRC)的支持。
进一步探索
更多信息:Latinus等人,“人类听觉皮层中语音身份的基于规范的编码”,当前的生物学(2013)dx.doi.org/10.1016/j.cub.2013.04.055
期刊信息:
当前的生物学
由...提供格拉斯哥大学
引用:Brain使用内部“平均语音”原型来识别谁在说话(2013年5月23日),2022年8月8日从//www.puressens.com/news/2013-05-05-brain-brain-internal-averation-voice-voice-voice-prototype.html
本文件受版权保护。除了出于私人研究或研究目的的任何公平交易之外,未经书面许可,不得复制任何部分。内容仅供参考。