信用:CC0公共领域
为了回答可以应用于广泛患者人口的医学问题,机器学习模型依靠来自各种机构的大型多样化数据集。然而,由于法律,隐私和文化挑战,卫生系统和医院往往抵抗分享患者数据。
根据期刊出版的一项研究,这是一种叫做联邦学习的新兴技术是对这种困境的解决方案科学报告,由宾夕法尼亚大学佩尔塞尔曼医学院放射学和病理学和实验室医学教练领导,博士领导。
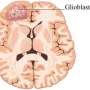
联合学习 - 以谷歌为键盘自动更正功能的方法首先实现的方法 - 在不交换它们的情况下跨多个分散的设备或服务器跨越多个分散设备或服务器进行算法。虽然该方法可能用于回答许多不同的医学问题,但是宾州医学研究人员已经表明,联邦学习专门在脑成像的背景下成功,通过能够分析脑肿瘤患者的磁共振成像(MRI)扫描并区分来自癌症地区的健康脑组织。
例如,在Penn医学中培训的模型可以分配给世界各地的医院。然后,医生可以通过输入自己的患者脑扫描来训练这个共享模型的顶部。然后将其新模型转移到集中式服务器。这些模型最终将与每个医院获得知识的共识模型,因此临床上有用。
“计算模型看到的数据越多,它会越好地了解问题,而且可以解决它旨在回答的问题越好,”巴纳斯说。“传统上,机器学习已经使用了一个机构的数据,然后它变得显然,这些模型不会对来自其他机构的数据进行概括或概括。”
在美国食品和药物管理局需要验证和批准联邦学习模式,然后可以作为医生的临床工具进行许可和商业化。但是,当该模型商业化时,它将有助于放射科医师,辐射脑药学家和神经外科医生对患者护理作出重要决策,贝卡斯说。根据美国脑肿瘤协会,今年将近80,000人诊断患有脑肿瘤。
“研究表明,当涉及到肿瘤界限时,不仅可以不同的医生可能有不同的意见,但同样的医生评估同一扫描可以看到一周内与接下来的一天的不同肿瘤边界定义,”他说。“人工智能允许医生具有更多关于肿瘤末端的更精确的信息,这直接影响患者的治疗和预后。”
为了测试联邦学习的有效性并将其与其他机器学习方法进行比较,巴卡斯与德克萨斯州安德森大学安德森癌症中心,华盛顿大学和匹兹堡大学的希尔曼癌中心合作,而英特尔公司贡献了隐私 -保护软件到项目。
该研究开始于一个模型,该模型是从被称为国际脑肿瘤细分的开源储存库的多机构数据预先培训,或者是挑战。BRATS目前提供了一个数据集,其中包括来自660名患者的磁共振成像(MRI)捕获的2,600次脑扫描。接下来,10家医院通过自己培训AI模型参加了研究患者数据。然后使用联合学习技术聚合数据并创建共识模型。
研究人员将联合学习与单一机构培训的模型以及其他协作学习方法进行了比较。通过将它们的扫描测试通过神经根学家手动注释的扫描来测量每种方法的有效性。与使用没有保护患者隐私的集中数据训练的模型相比,联合学习能够相同地执行几乎(99%)。调查结果还指出,通过数据私有,多机构合作可以增加对数据的访问可以使模型性能有益。
本研究的调查结果为宾夕法尼亚州国家癌症研究所国家癌症研究所获得了120万美元的批准,为宾夕法尼亚州国家癌症研究所获得了120万美元的批准而铺平了更大,雄心勃勃的合作。今年。伊利欧尔宣布的贝卡斯将领导该项目,其中九个国家的30个机构将利用联邦学习方法培训AI共识模型关于脑肿瘤数据。该项目的最终目标是为任何医院使用的临床医生创建一个开源工具。Penn生物医学图像计算和分析中心(CBICA)的工具的开发是由高级软件开发者Sarthak Pati,MS领导的。
研究匹兹堡大学医学院放射副教授的研究共同作者Rivka Colen表示,本文和较大的联邦学习项目开辟了甚至更多地用处的医疗智能用途的可能性。
“我认为这是一个巨大的比赛更换器,”Colen说。“辐射瘤是放射学到病理学的基因组。AI将彻底改变这一领域,因为现在,作为放射科学家,我们所做的大部分是描述性的。随着深度学习,我们能够提取隐藏的信息数字化图像层。“
更多信息:科学报告(2020)。DOI:10.1038 / S41598-020-69250-1
信息信息:科学报告
由...提供宾夕法尼亚大学的佩尔尔曼医学院